 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Aware Constellation Learning for Image Transmission
May 29, 2026Semantic communication has demonstrated significant potential for image transmission, especially in bandwidth-limited and low signal-to-noise ratio scenarios. However, most existing methods are based on analog transmission, which poses challenges to the compatibility with existing digital communication systems. Existing digital semantic communication methods commonly adopt conventional quadrature amplitude modulation constellations, which mismatch the empirical distribution of semantic features produced by the semantic encoder. This paper proposes a distribution-aware learnable modulation for semantic communication framework, which bridges semantic feature representations and discrete modulation through constellation learning. Specifically, a learnable constellation module, initialized with an amplitude phase shift keying geometric prior, is developed to refine the constellation geometry as a trainable codebook, enabling modulation symbols to better align with the distribution of semantic features. To enable end-to-end optimization, a two-stage training strategy is introduced, combining differentiable soft assignment with straight-through estimator. Simulation results show that the proposed framework consistently outperforms existing digital semantic communication schemes and achieves performance comparable to advanced analog methods.
MIMO-OTFS-Based Semantic Communication for High-Mobility Scenarios
May 28, 2026In high-mobility scenarios with time-frequency doubly-selective channels, existing semantic communication systems suffer significant performance degradation. To address this issue, we propose a semantic communication framework that synergistically integrates multiple-input multiple-output orthogonal time frequency space (MIMO-OTFS) with semantic-aware sub-channel allocation. First, an entropy module is employed to evaluate importance of different semantic features, and the Kendall correlation coefficient is used to quantify the alignment between semantic importance and sub-channel conditions. Subsequently, joint optimization of the encoder and decoder is achieved through a comprehensive loss function that balances image classification accuracy, reconstruction quality, and sub-channel matching degree. Experimental results confirm the superior reconstruction quality of our proposed framework compared to conventional semantic communication systems based on orthogonal frequency division multiplexing in high-mobility channel environment.
Efficient Learned Image Compression without Entropy Coding
May 22, 2026Entropy coding is widely used in typical learned image compression (LIC) that converts latents into a compact bitstream. However, entropy coding is typically sequential and becomes the coding latency bottleneck. To overcome it, we present Entropy-Coding Free Learned Image Compression (EF-LIC), a multi-rate framework that generates compact representation by removing statistical and correlation redundancy with low coding latency. First, we introduce unconstrained vector quantization and prove that its index distribution approaches the maximum-entropy bound, yielding minimal statistical redundancy. Second, we propose a context-conditioned autoregressive transform that directly reparameterizes the latents to reduce inter-dependency. Theoretical analysis shows that EF-LIC can remove correlation redundancy as effectively as typical LIC with entropy coding, leading to comparable compression performance. Experiments show EF-LIC achieves up to 67.86% bitrate reduction over MS-ILLM on Kodak with LPIPS. Ablation studies further show EF-LIC matches the compression performance of its entropy-coding based variant while achieving over $3\times$ faster encoding and $5\times$ faster decoding.
Perception-Aware Video Semantic Communication
May 19, 2026Ultra-high-resolution streaming and emerging immersive services are driving rapidly increasing wireless video traffic. However, perceptually pleasing video transmission over bandwidth-limited and latency-constrained wireless links remains challenging for conventional separated source-channel systems, which primarily target bit-level reliability and often suffer performance degradation under short-blocklength transmission. In addition, pixel-level distortion optimization does not necessarily align with human perception, while existing learned video codecs may incur high complexity and raise deployment issues. This paper proposes PVSC, a perception-aware video semantic communication framework for real-time wireless video transmission. PVSC eliminates explicit motion-vector transmission and exploits spatio-temporal feature coding to generate compact and channel-robust symbol streams. It also specifies side-information formatting, reference-buffer management, and lightweight rate control, enabling stable receiver-side reconstruction and bandwidth-adaptive inference with a single model. Extensive experiments demonstrate that PVSC achieves superior performance across diverse datasets, resolutions, GOP configurations, and channel conditions. Compared with the engineered ``VTM + 5G LDPC'' baseline, PVSC saves up to about 75% and 87% bandwidth at comparable LPIPS and DISTS, respectively, while enabling real-time inference on a single NVIDIA RTX 4090 GPU.
Generalizable 3D Gaussian Splatting enabled Semantic Coding for Real-Time Immersive Video Communications
Apr 28, 2026Real-time immersive video communications, particularly high-fidelity 3D telepresence, necessitates a synergistic balance between instantaneous dynamic scene reconstruction and high-efficiency data transmission. While recent advancements in feed-forward 3D Gaussian Splatting (3DGS) have enabled real-time rendering, performing multi-view video coding and 3D reconstruction in a decoupled manner leads to suboptimal compression efficiency and high computational complexity. To address this, we propose GS-SCNet, the first unified end-to-end framework that seamlessly integrates generalizable 3DGS reconstruction with a dedicated deep Semantic Coding pipeline. Our architecture is underpinned by two core technical contributions: (i) we introduce a Disparity-Guided Parallel Semantic Codec that exploits epipolar geometric priors to facilitate cross-view contextual interaction via disparity compensation and semantic fusion, thereby enabling real-time parallel processing of stereo streams while significantly enhancing rate-distortion performance, and (ii) we develop a Lightweight Gaussian Parameter Predictor which directly projects decoded semantic latents into 3DGS attributes, obviating the need for intermediate pixel-domain reconstruction. By coupling the codec with the task-specific predictor, our framework extracts geometric correlations only once, effectively eliminating the redundant computational bottleneck inherent in conventional decoupled paradigms. Extensive evaluations on both synthetic and real-world human datasets demonstrate that GS-SCNet achieves a superior trade-off across compression efficiency, rendering quality, and real-time performance. Notably, our framework exhibits strong cross-domain generalization and robustness against compression artifacts when applied to out-of-domain real-world data, significantly outperforming conventional decoupled transmission paradigms.
Semantic Feature Multiple Access Empowered Integrated Learning and Communication Networks
Apr 10, 2026Integrated learning and communication (ILAC) unifies learned transceivers with radio resource management, where semantic feature multiple access (SFMA) enables paired users to superpose their learned representations over shared time-frequency resources. Unlike conventional multiple access schemes, SFMA interference arises in the learned feature space and depends jointly on the user pair, the transmit power, and the compression ratio. This coupling ties binary pairing decisions to continuous resource variables, yielding a mixed-integer non-convex optimization problem. To address this problem, we first propose similarity-conditioned SFMA (SC-SFMA), a Swin Transformer-based transceiver whose dual-conditioned similarity modulator (DC-SimM) gates cross-user feature fusion according to the inter-user semantic similarity. We then characterize the resulting pair-dependent interference by a bivariate logistic function parameterized by transmit power and compression ratio, thereby bridging the learned transceiver with network-level optimization. On this basis, we formulate a sum-rate maximization problem subject to per-user distortion, latency, energy, power, and bandwidth constraints. To solve this problem, we develop a three-block alternating optimization algorithm that integrates dual-decomposition-assisted compression ratio allocation, trust-region successive convex approximation (SCA) for joint power-bandwidth optimization, and dynamic feasible graph-based user pairing. Simulation results show that SC-SFMA achieves considerable peak signal-to-noise ratio (PSNR) and multi-scale structural similarity index measure (MS-SSIM) gains over deep joint source-channel coding (JSCC) and separation-based baselines. The proposed optimization framework attains significant sum rate improvements over conventional multiple access baselines.
Toward Robust Semantic Communications: Proactive Importance-Ordered Restructuring for Enhanced Unequal Error Protection
Apr 01, 2026Semantic communications (SemCom) is a promising task-oriented paradigm in which semantic features exhibit non-uniform importance. Consequently, unequal error protection (UEP), which allocates resources based on semantic importance, plays a pivotal role in maximizing system utility. However, most existing schemes adopt passive importance evaluation, which neither proactively reshapes the importance distribution nor explores its impact on UEP performance. In this paper, we propose a novel importance-ordered semantic feature restructuring (ISFR) scheme that proactively enforces a descending importance hierarchy and jointly optimizes multi-dimensional resources to improve system utility. Specifically, modules with decreasing retention probabilities and increasing distortion levels are employed, which drive the model to concentrate key semantics into front-end features and thus strengthen importance differentiation. Moreover, a joint optimization problem that jointly optimizes channel matching, feature selection, modulation schemes, and power allocation is formulated to minimize the importance-weighted total semantic distortion. To solve this non-convex problem, a hierarchical decoupling strategy is proposed, which decomposes it into four tractable subproblems. This approach leverages the ordered prior to drastically prune the search space for feature selection and modulation, while integrating greedy-based channel matching and convex power allocation. Simulation results demonstrate that the proposed ISFR scheme outperforms traditional uniform importance-based schemes under harsh channel conditions and limited resources, validating the significant robustness improvement enabled by the concentration of key semantic information.
ProGIC: Progressive and Lightweight Generative Image Compression with Residual Vector Quantization
Mar 03, 2026Recent advances in generative image compression (GIC) have delivered remarkable improvements in perceptual quality. However, many GICs rely on large-scale and rigid models, which severely constrain their utility for flexible transmission and practical deployment in low-bitrate scenarios. To address these issues, we propose Progressive Generative Image Compression (ProGIC), a compact codec built on residual vector quantization (RVQ). In RVQ, a sequence of vector quantizers encodes the residuals stage by stage, each with its own codebook. The resulting codewords sum to a coarse-to-fine reconstruction and a progressive bitstream, enabling previews from partial data. We pair this with a lightweight backbone based on depthwise-separable convolutions and small attention blocks, enabling practical deployment on both GPUs and CPU-only devices. Experimental results show that ProGIC attains comparable compression performance compared with previous methods. It achieves bitrate savings of up to 57.57% on DISTS and 58.83% on LPIPS compared to MS-ILLM on the Kodak dataset. Beyond perceptual quality, ProGIC enables progressive transmission for flexibility, and also delivers over 10 times faster encoding and decoding compared with MS-ILLM on GPUs for efficiency.
Joint Semantic-Channel Coding and Modulation for Token Communications
Nov 19, 2025In recent years, the Transformer architecture has achieved outstanding performance across a wide range of tasks and modalities. Token is the unified input and output representation in Transformer-based models, which has become a fundamental information unit. In this work, we consider the problem of token communication, studying how to transmit tokens efficiently and reliably. Point cloud, a prevailing three-dimensional format which exhibits a more complex spatial structure compared to image or video, is chosen to be the information source. We utilize the set abstraction method to obtain point tokens. Subsequently, to get a more informative and transmission-friendly representation based on tokens, we propose a joint semantic-channel and modulation (JSCCM) scheme for the token encoder, mapping point tokens to standard digital constellation points (modulated tokens). Specifically, the JSCCM consists of two parallel Point Transformer-based encoders and a differential modulator which combines the Gumel-softmax and soft quantization methods. Besides, the rate allocator and channel adapter are developed, facilitating adaptive generation of high-quality modulated tokens conditioned on both semantic information and channel conditions. Extensive simulations demonstrate that the proposed method outperforms both joint semantic-channel coding and traditional separate coding, achieving over 1dB gain in reconstruction and more than 6x compression ratio in modulated symbols.
Multi-Task Semantic Communications via Large Models
Mar 28, 2025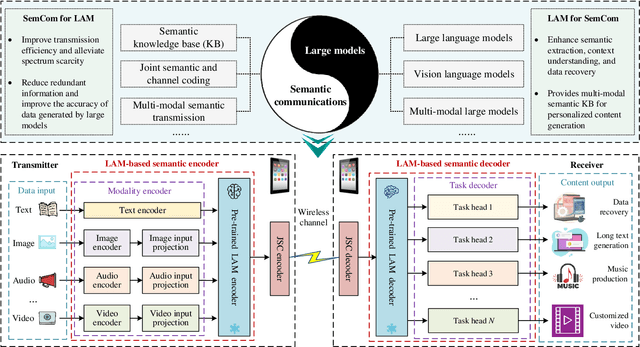
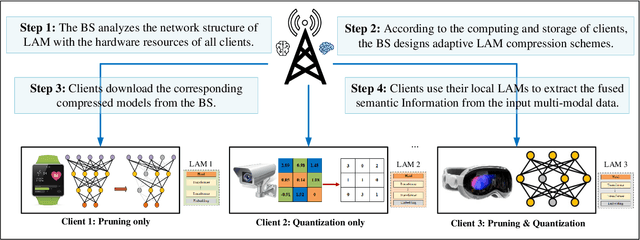
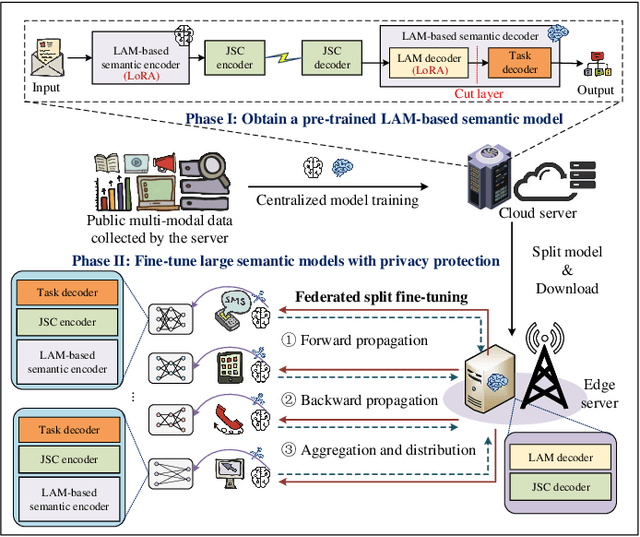
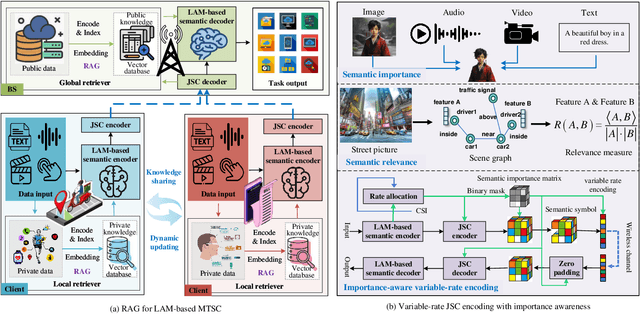
Artificial intelligence (AI) promises to revolutionize the design, optimization and management of next-generation communication systems. In this article, we explore the integration of large AI models (LAMs) into semantic communications (SemCom) by leveraging their multi-modal data processing and generation capabilities. Although LAMs bring unprecedented abilities to extract semantics from raw data, this integration entails multifaceted challenges including high resource demands, model complexity, and the need for adaptability across diverse modalities and tasks. To overcome these challenges, we propose a LAM-based multi-task SemCom (MTSC) architecture, which includes an adaptive model compression strategy and a federated split fine-tuning approach to facilitate the efficient deployment of LAM-based semantic models in resource-limited networks. Furthermore, a retrieval-augmented generation scheme is implemented to synthesize the most recent local and global knowledge bases to enhance the accuracy of semantic extraction and content generation, thereby improving the inference performance. Finally, simulation results demonstrate the efficacy of the proposed LAM-based MTSC architecture, highlighting the performance enhancements across various downstream tasks under varying channel conditions.